42 é a resposta. Qual é a pergunta sobre a relação entre Computação e Linguística e tudo o mais?

Neste artigo para a Horizontes, Adelaide, Doutora em Linguística, desenvolve uma discussão sobre a relação da Linguística com a Computação, trazendo e discutindo exemplos que mostram suas visões sobre como essas duas áreas se relacionam. Nas palavras da autora, “Tentar simplesmente usar um sistema de outra língua para lidar com o PT-BR não funciona, devido às diferenças estruturais, semânticas e pragmáticas entre as línguas naturais. E, nesse sentido, o diálogo entre Linguística e Computação, no Brasil, tem muito a avançar.” Boa leitura! (Roberto Pereira, Editor Geral)
por Adelaide H.P. Silva
No “Guia do Mochileiro das Galáxias”, uma inteligência artificial, Deep Thought, é procurada pelo povo magrateano, que lhe pede uma resposta definitiva para a vida, o universo e tudo o mais. A resposta — como era de se esperar — não era simples, e Deep Thought levou sete milhões e meio de anos para calculá-la.
Chegado o Dia da Resposta, dois descendentes dos dois programadores que propuseram a questão vão até Deep Thought que, finalmente, declara ter conseguido chegar a uma solução. E afirma: “42 é a resposta”. Notando a clara surpresa e decepção dos magrateanos, Deep Thought lhes diz que o problema não é a resposta, mas as perguntas e a maneira vaga pela qual foram elaboradas.
Já que é preciso formular boas perguntas na busca por boas respostas, este artigo não tem a pretensão de propor questões tão complexas quanto as que se esperava que Deep Thought pudesse resolver. Ao contrário, o artigo propõe algumas questões acerca da relação entre Computação e Linguística. E eu busco responder a essas questões sem a pretensão de oferecer soluções definitivas. Muito pelo contrário: as respostas nada mais são do que reflexões de uma linguista que, ao realizar um estágio pós-doutoral em Informática, tenta traçar relações entre duas ciências que compartilham a preocupação de pensar a linguagem — natural ou artificial — e a relação entre linguagem e usuários.
Neste texto eu proponho três perguntas: as duas primeiras perguntas — “como a Linguística aborda a linguagem?” e “que aspectos permitem traçar convergência entre Computação e Linguística?” — tentam dar conta da vida. Considerando o universo, a terceira pergunta é mais pontual — “que resultados produz a interação entre Computação e Linguística?”.
Como a Linguística aborda a linguagem?
Qualquer manual de Linguística que consultemos nos diz que a Linguística é a ciência que estuda a linguagem. E essa é uma resposta equivalente a 42, já que não esclarece o que seja a linguagem. E a pergunta “o que é a linguagem?”, que não é trivial, tem mais de uma resposta possível, porque a resposta depende do paradigma teórico que o linguista segue.
Apesar das diferenças epistemológicas entre paradigmas distintos, como estruturalismo e gerativismo, por exemplo, há um aspecto em comum entre eles: todos tomam como objeto de estudo as línguas naturais.
Antes de seguir, preciso fazer dois esclarecimentos: 1) daqui em diante emprego o termo “língua” como a manifestação concreta da linguagem, usada como código de comunicação pelos humanos; 2) por “língua natural” os linguistas entendem línguas que se desenvolvem sem um planejamento prévio, através do uso por um determinado grupo de indivíduos. Essa característica distingue línguas como o esperanto ou o quenya, por exemplo, de línguas como o francês e o hausa. Distingue, igualmente, linguagens formais, como as linguagens de programação, de línguas como o russo e o árabe.
|
esperanto |
quenya |
|
Desenvolvida por Zamenhof em 1887, o esperanto tem por objetivo ser uma língua universal, com estrutura previsível, livre de variações. Por exemplo, a desinência -a sinaliza adjetivos, enquanto -o sinaliza substantivos. |
Criada por J. R. R. Tolkien por volta de 1910, quenya é uma língua fictícia utilizada pelos elfos em seu legendarium, e utiliza um sistema especial de escrita chamado Tengwar. |
Para responder minha primeira pergunta, começo chamando a atenção para o fato de que a abordagem que a Linguística dá à língua é bastante diferente daquela dada pela gramática normativa. A abordagem da gramática normativa, que nós aprendemos na escola, trata de estabelecer “formas corretas” e “formas erradas”, que não devemos empregar quando falamos uma língua.
E qual é o critério que define o que é uma forma correta? No caso do português brasileiro (PT-BR), os critérios são elaborados a partir de textos produzidos por escritores portugueses no século XIX. E isso pode explicar a grande distância entre norma e uso que conhecemos muito bem, e que faz com que as aulas de língua portuguesa do colégio acabem sendo aulas de uma língua estrangeira, que ninguém fala. Mas essa é outra longa história.

Vamos voltar à maneira como a Linguística aborda a linguagem. A premissa fundamental, para essa ciência, é a de que existem formas diversas, que podem coocorrer num mesmo registro. Isto significa que a Linguística não se preocupa em prescrever – ou determinar – quais seriam as “formas certas” que os falantes de uma língua devem utilizar. À Linguística interessa descrever as formas em uso para, então, tentar explicar por que aquelas formas são possíveis na língua. Assim, por exemplo, a sentença (i) é perfeitamente possível em português:
(i) Elei viu elej ontem no cinema. ==> ((Ele)(viu ele)((ontem)(no cinema)))
Embora a gramática normativa diga que pronome pessoal não pode funcionar como objeto direto de um verbo, o que tornaria “errada” a sequência “viu ele”, nós produzimos sentenças como (i) recorrentemente. Mais: como falantes da língua portuguesa, sabemos que a primeira instância de “ele” remete a alguém, no mundo, que não é a mesma pessoa à qual remete a segunda instância de “ele”. Essa é a razão pela qual cada instância de “ele” recebe índices diferentes em (i).
Por que produzimos essa sentença na língua, sem estranharmos? Uma explicação possível decorre da observação sobre o ordenamento de constituintes no português brasileiro. Linguistas como Coelho et al. (2008) notam que a ordem sujeito-verbo-objeto tem-se tornado mais frequente na língua do que outro ordenamento, igualmente possível, como verbo-sujeito-objeto, por exemplo.
Ora, os falantes nativos de PT-BR sabem que um verbo como “ver” seleciona dois argumentos, um que funciona como sujeito e outro, como objeto direto. E sabem que o termo à esquerda do verbo é o argumento que funciona como sujeito, enquanto o termo à direita funciona como objeto direto. Logo, se os falantes sabem que a posição na sentença marca a função sintática do pronome, não é preciso usar um conjunto de pronomes específicos para a função de sujeito e outro conjunto, diferente do primeiro, para a função de objeto.
Isto é o que a norma nos diz: há pronomes do caso reto (que devem funcionar como sujeito) e pronomes do caso oblíquo (que devem funcionar como objeto). Porém, como, na língua em uso, a posição do constituinte determina sua função, os falantes podem “enxugar” o inventário de pronomes.
É possível “traduzir” a observação acima em relações de precedência. Observe:
(ii) ((Ele)(viu ele)((ontem)(no cinema)))
Essa notação separa o argumento externo (sujeito) do argumento interno (objeto) do verbo, e sinaliza que o objeto interno do verbo forma, com ele, um mesmo constituinte sintático. A implicação dessa notação por ordem de precedência é a de que nós processamos o chunk “viu ele” separado do chunk “ele”. O processamento separado de cada chunk, por sua vez, nos permite atribuir um referente distinto a cada “ele”, assumindo-se, como faço aqui, uma relação entre o nível sintático e o nível semântico da língua.
Passo, agora, a um novo exemplo que ilustra como a Linguística aborda a linguagem. Esse era o título de uma notícia do portal G1, publicada em 13 de agosto de 2020:

(iii) Polícia indicia estudante picado por naja, mãe, padrasto e outras 9 pessoas.
A sentença em (iii) exemplifica um caso de ambiguidade estrutural, como mostram as duas anotações a seguir:
(iv) ((Polícia indicia estudante picado por naja,)( mãe, padrasto e outras 9 pessoas.))
(v) ((Polícia indicia estudante picado) (por naja, mãe, padrasto e outras 9 pessoas.))

Um dos vários memes sobre a naja compartilhados nas redes sociais.
A ambiguidade estrutural corresponde justamente ao fato de haver duas representações possíveis para os constituintes de uma mesma sentença, como sinalizado em (iv) e (v).
Muito provavelmente, quem escreveu a manchete pensava no sentido atrelado à representação em (iv), isto é, a polícia indiciou o estudante que foi picado por uma naja. Além dele, indiciou sua mãe, seu padrasto e outras nove pessoas. Mas a ordem de constituintes que o autor da manchete resolveu empregar licencia um outro sentido, o de que a polícia indiciou o estudante que foi picado por uma cobra naja, pela mãe, pelo padrasto e por mais nove pessoas. Neste caso, haja soro antiofídico para curar o pobre rapaz!
A brincadeira serve para ilustrar o ponto a que quero chegar: para explicar como uma língua funciona, os linguistas podem lançar mão de relações lógicas que estruturam as sentenças e da verificação sobre como tais relações operam numa língua.
Esta estratégia — é importante salientar — não é diferente daquela que matemáticos e cientistas de computação utilizam para pensar linguagens artificiais, porque também assume que os elementos dentro de uma mesma estrutura parentética sejam processados conjuntamente e que haja uma relação de precedência entre elementos dentro e fora de uma estrutura parentética, bem como entre as estruturas parentéticas propriamente. Ao fim e ao cabo, a forma lógica de (iv) e (v) não tem problema algum. Mas o sentido pode não ser exatamente o esperado.
Exemplos como este, recorrentes nas línguas naturais, reforçam o argumento de que a estrutura formal de um enunciado e seu sentido guardam estreita relação, sendo mesmo possível defender, como fazem autores como Richard Montague, que constituintes formados pelas regras sintáticas de uma língua são simultaneamente interpretados pelas regras semânticas correspondentes. Essa visão se contrapõe a uma outra, segundo a qual sintaxe e semântica, isto é, estrutura e sentido, são independentes numa língua.
A independência entre sintaxe e semântica é defendida por Chomsky, em seu Syntactic Structures, a partir da sentença “Colorless green ideas sleep furiously”. Chomsky defende que, como a linguagem humana não é um sistema fechado, podemos formar sentenças que nunca ouvimos antes, seguindo as regras de boa formação de uma língua específica. E, nesse sentido, podemos dizer que a sentença “Colorless green ideas sleep furiously” é bem formada tanto do ponto de vista morfológico (relativo à estrutura interna das palavras), como do ponto de vista sintático.
Sob o aspecto morfológico, sabemos, e.g., que “furiously” é advérbio, já que termina com o sufixo -ly, característico de advérbios de modo em inglês. Mais: identificamos colorless como um adjetivo, já que -less é usado para a formação de outros adjetivos na mesma língua. Adicionalmente, sabemos que o sufixo -less introduz sentido de negação; portanto, algo que é “colorless” é desprovido de cor. Sob o aspecto sintático, a boa formação da sentença se traduz no fato de que dois adjetivos (colorless e green) precedem o substantivo (ideas), seguindo a ordem de constituintes default do inglês, e o verbo ocupa a posição canônica dentro de uma sentença declarativa de língua inglesa: sucedendo o sujeito.
Apesar de ser bem formada, não há como verificar o valor de verdade dessa sentença; por isso, como argumentam os semanticistas, como o próprio Montague, não é possível atribuir-lhe um significado. E, se a sentença não tem significado, os falantes não encontram motivo para usá-la.
Neste ponto, podemos pensar que a Computação exibe um exemplo análogo: eu posso fazer um código com a sintaxe toda correta, mas com uma estrutura lógica problemática que gera, ao fim e ao cabo, um programa que roda, mas que dá, como saída, um resultado diferente do esperado. Então, também do ponto de vista da Computação, parece-me possível pensar na interdependência entre sintaxe e semântica (isto é, estrutura lógica).
Este é já um primeiro ponto de convergência entre Linguística e Computação. E é possível traçá-lo porque, diferentemente da gramática tradicional, a Linguística se preocupa em explicar como e por que os enunciados de uma língua são como são. Para isso, a Linguística recorre a tratamentos formais semelhantes àqueles que a Computação utiliza. Na próxima seção, eu tento aprofundar um pouquinho mais essas considerações.
Que aspectos permitem traçar convergência entre Computação e Linguística?
Dois aspectos merecem atenção: 1. Arquitetura e processamento da linguagem e 2. Análise de Dados.
Arquitetura e processamento da linguagem
Um dos aspectos sob os quais Linguística e Computação me parecem convergir é a arquitetura da linguagem. Tomo linguagem, aqui, sob uma acepção bem genérica, no sentido largo de um sistema dotado de estruturas e que visa à comunicação, tanto a de humanos como a de máquinas.
A linguagem humana se compõe de múltiplas facetas distintas entre si. Assim, por exemplo, a linguagem tem uma estrutura abstrata, com representações de fenômenos de natureza diversa, como aqueles relacionados ao nível sonoro e que nos permitem saber, por exemplo, a razão pela qual, num processo de derivação para formar um substantivo a partir do adjetivo “amável”, nós produzimos “amabilidade”, num processo que envolve não só a alternância entre /v/ e /b/, mas também a alternância entre as vogais /e/ e /i/ do radical.
A linguagem humana tem também representações de estruturas de sentenças que nos permitem saber, e.g., que uma sentença interrogativa do tipo “wh” no português como “Quem a Maria encontrou no cinema?”, requer o movimento do pronome “quem”, a partir de sua posição default. Essa posição equivale a “A Maria encontrou quem no cinema?”. Nela, o objeto direto do verbo “encontrar” é “quem”. Ao ser movido para o início da sentença, “quem” deixa um vestígio na sua posição inicial.
Com aspectos tão diversificados, é impossível propor um modelo que explique toda a linguagem. A solução encontrada pelos linguistas para compreender e explicar seu objeto de estudo foi assumir que a linguagem se constitui de blocos, ou módulos, que embora distintos se inter-relacionam.
Assim, existe um módulo relacionado à produção dos sentidos de um enunciado; um módulo responsável pelo concatenamento de palavras para formar unidades maiores, como as sentenças; um módulo responsável pelo concatenamento de unidades menores, como raízes e afixos, para a formação de palavras; um módulo responsável por associar acento, estrutura rítmica e estrutura silábica a sequências de sons.
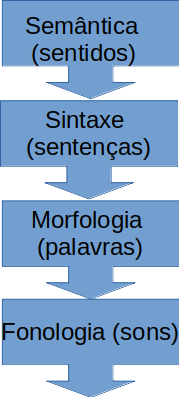
Explicar como cada módulo funciona é tarefa de diferentes disciplinas da Linguística, como semântica, sintaxe, morfologia e fonologia. Os linguistas assumem, então, que a compreensão sobre a maneira como a linguagem é processada em cada bloco pode nos ajudar a compreender a linguagem como um todo.
Neste sentido, parece-me haver grande proximidade entre essa perspectiva e o funcionamento de linguagens de programação, sobretudo se consideramos que vários blocos distintos, mas inter-relacionados, podem constituir um programa que resolva uma tarefa qualquer.
Assim, é possível termos uma estrutura condicional, num bloco, e uma estrutura de repetição noutro bloco. Ordenados, esses blocos geram, como resultado, um algoritmo que possibilitará a um sistema desenvolver uma tarefa qualquer. Conforme observam Sedgewick; Wayne (2017:01), ao introduzirem as bases da programação:
“alguns poucos blocos são suficientes para que possamos escrever programas que podem nos ajudar a resolver todos os tipos de problemas fascinantes, mas que seriam inacessíveis de outra forma”.
A concepção modular sobre a arquitetura da linguagem — humana e de programação — me parece refletir-se numa concepção possível sobre o seu processamento. Para tratar da maneira como a linguagem humana é processada, parto de uma abordagem “top-down”, tal qual discutida por Levelt (1989), a partir da proposição do esquema a seguir:
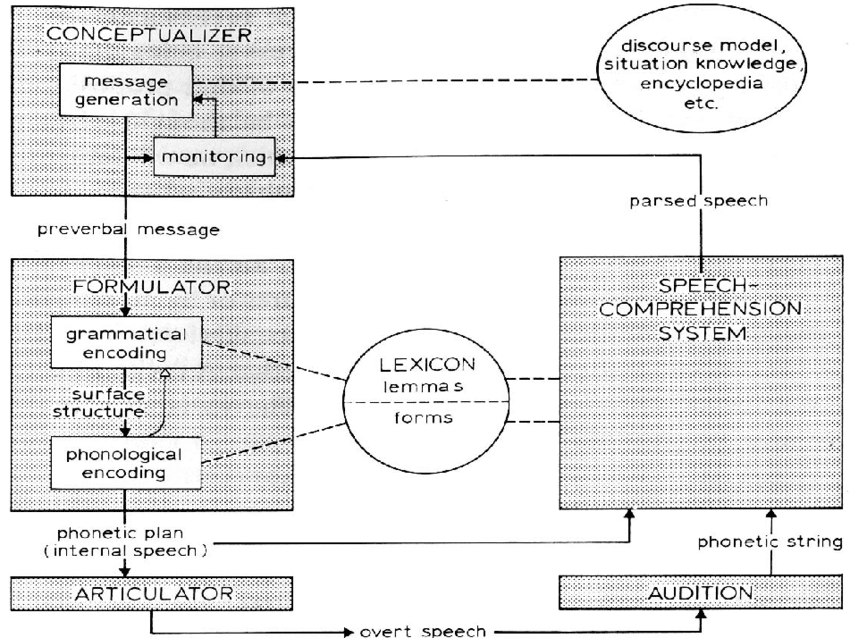
Esquema de processamento da linguagem, cf Levelt (1989:09)
Nesse esquema, um módulo conceptualizador, responsável pela formulação e o monitoramento de uma mensagem, gera o que o linguista denomina “mensagem pré-verbal”, uma espécie de “intenção” de um enunciado, ou seja, há um sentido geral de uma mensagem, mas ainda não há uma mensagem propriamente.
Para tornar a mensagem concreta, ao ponto de ser enunciada, a “mensagem pré-verbal” deve dar entrada no módulo “formulador”. Ali, ela é codificada gramaticalmente, isto é, a mensagem passa por um dispositivo como um “parser” morfossintático, que estabelece as fronteiras entre sentenças constitutivas da mensagem e, em cada sentença, atribui as fronteiras dos constituintes dessas sentenças, como sintagmas nominais e sintagmas verbais.
Dentro de cada sintagma, os componentes etiquetados como nomes ou verbos, por exemplo, recebem, a depender da língua, marcas morfológicas que podem carregar informação de tempo e aspecto verbais ou gênero e número dos substantivos. Tem-se, assim, uma “estrutura superficial”.
A estrutura superficial, já com as informações sobre constituintes sintáticos e morfológicos do enunciado visado, dá entrada no módulo fonológico, onde é processada de modo que sejam atribuídos acentos lexicais (correspondente à sílaba mais intensa de uma palavra) e acentos frasais (a sílaba mais proeminente de uma sentença), por exemplo, ou fronteiras de sílaba e de outras unidades prosódicas.
Nesse módulo são ainda implementados processos fonológicos, específicos de língua, sobre uma unidade sonora específica ou sobre uma sequência linear de unidades sonoras. Esse procedimento gera o “plano fonético” de um enunciado, que dá entrada num módulo “articulador”, responsável pelos comandos neuromotores que ativam os articuladores envolvidos na produção da cadeia sonora do enunciado planejado. O enunciado, finalmente, é “falado”.
A fala é o output do sistema de processamento do enunciado. Neste ponto, deve estar claro que temos aí um processamento procedural e no qual a ordem importa: ao mesmo tempo em que a entrada de um módulo é a saída do módulo imediatamente precedente, uma eventual inversão da ordem de processamento alteraria o output e, no limite, geraria um enunciado inexistente numa língua.
O output do sistema, ou “fala aberta”, chega ao interlocutor do sujeito que gerou a mensagem. O interlocutor deve decodificar o enunciado seguindo as pistas que a fala aberta carrega sobre os níveis fonológico e morfossintático para, assim, chegar ao sentido do enunciado. É este procedimento que acontece no módulo de “compreensão” do esquema de Levelt.
Cabe esclarecer que Levelt prevê que tanto quem produz como quem recebe a mensagem tem um léxico — ou conjunto de unidades, como palavras — comum e compartilha um conhecimento pragmático-discursivo que sinaliza, e.g., que podemos agradecer alguém usando a expressão “Valeu!”, mas o uso dessa expressão se circunscreve a uma situação de fala informal. Se queremos expressar agradecimento, numa situação que requer maior formalidade, é mais adequada a forma “Obrigada!”.
Se consideramos, agora, a maneira como uma linguagem artificial é processada, podemos reconhecer alguns pontos de convergência com o processamento descrito para a linguagem natural.
Propósito
Parece-me possível dizer que, antes de escrever um programa, temos um conceito daquilo que ele deverá fazer, que corresponderia à “mensagem pré-verbal”. Assim, por exemplo, podemos ter o conceito de um programa que receba como entrada um conjunto de números naturais e que distinga números pares de números ímpares. Podemos também planejar que, dentro de cada conjunto — o de números pares e o de números ímpares — o programa nos ofereça informações como o maior número, a soma dos valores em cada conjunto e a média aritmética desses valores.
Essa “mensagem pré-verbal” precisa, na sequência, ser processada gramaticalmente, o que implica a formulação de sub-rotinas, cada uma composta de funções e variáveis. A sintaxe que orienta a declaração das funções e das variáveis é específica de uma linguagem de programação, assim com a sintaxe de uma língua natural é específica daquela língua. E o “nome” das funções pertence a um léxico pré-estabelecido, assim como no processamento da linguagem humana.
Cabe comentar que um problema de sintaxe pode levar, e.g., a uma declaração “agramatical” de uma função, isto é, uma declaração que a linguagem não reconhece como pertencente a ela como, por exemplo, o emprego de ponto e vírgula na declaração de uma função while em Python.
Ordem
A ordem em que as funções são declaradas num programa, muitas vezes, pressupõe uma relação de precedência no processamento e, consequentemente, implementação de uma função. Colocar uma estrutura condicional dentro de uma estrutura de repetição, por exemplo, gera um resultado obviamente diferente daquele que temos ao colocar uma estrutura condicional antecedendo uma estrutura de repetição.
Ainda seguindo a analogia entre o processamento de linguagem de programação com o processamento de linguagem natural, podemos dizer que a “estrutura superficial” do processamento de uma linguagem de programação corresponde ao código finalizado e a “fala aberta”, ao output do programa, ou seja, à implementação das tarefas especificadas na conceptualização.
Recursão
Cabe ainda uma última consideração sobre o modelo procedural de processamento de linguagem, proposto por Levelt. O modelo de sintaxe gerativa, elaborado por Chomsky, e ainda hoje largamente empregado na Linguística, é também um modelo procedural e assume que a linguagem humana pode ser reduzida a uma estrutura lógico-formal do tipo S((SN(Det,N))(SV(V(SN(Det,N))))) e que é possível gerar “fala aberta” a partir de uma “mensagem pré-verbal”.
A transformação de uma estrutura abstrata noutra, concreta, é implementada por um conjunto de regras que aplicam, sobre a “mensagem pré-verbal”, uma estrutura lógico-formal como a exemplificada.
Um conjunto de regras ordenadas aplica as relações lógico formais e gera um enunciado como “O programador escreve um código”. Assim:
(vi) S((SN(ODet, programadorN))(SV(escreveV(SN(umDet,códigoN)))))
Preenchidas cada uma das posições do enunciado com palavras da língua, elas se agrupam ordenadamente, em constituintes maiores, SN e SV. O agrupamento resulta do princípio da composicionalidade, que Chomsky aponta como fato característico da linguagem humana, universal.
Considerando o esquema proposto por Levelt, a composicionalidade se aplica no módulo formulador, mais especificamente na codificação gramatical. Há um outro princípio, que se processa nesse mesmo ponto e que também é universal: a recursividade que permite aos falantes do português criarem um enunciado como (vii):
(vii) Alice caiu na toca do coelho, que a levou até o Chapeleiro Louco, que tomava chá com o Gato Cheshire, que escapou de ser decapitado pela Rainha de Copas, que joga críquete com flamingos.
Em (vii), o pronome relativo que inicia cada sentença encaixada toma como antecedente um termo da sentença precedente. Além disso, cada sentença introduz uma informação nova, recuperada pela seguinte, numa iteração, de modo que as informações – e o próprio sentido – do enunciado vão se “empilhando”. Esse processo é obviamente muito parecido com o que temos na Computação.
Análise de dados
Linguística e Computação também convergem quanto à maneira como tratam de dados. O diagrama na figura abaixo esquematiza como a Computação – em particular a ciência de dados – atua:
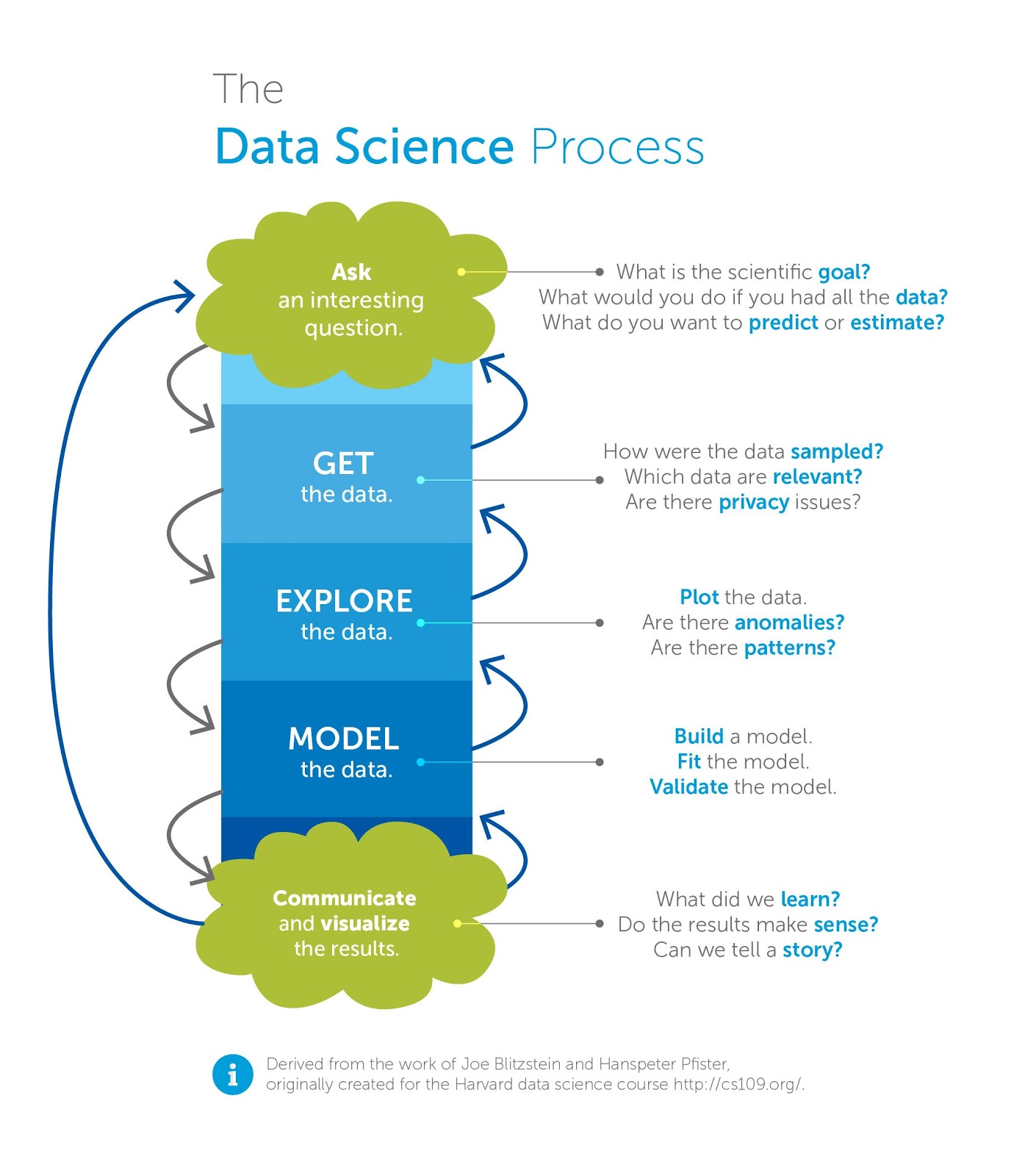 Esquema da atuação da ciência de dados, in http://www.cherhan.net/data-scientist-really/
Esquema da atuação da ciência de dados, in http://www.cherhan.net/data-scientist-really/
Pensando na analogia que eu estou propondo, podemos fazer uma “pergunta interessante”: “como traduzir a sentença ‘Yes, we can!’ para os diferentes dialetos italianos?”
Para respondê-la, um pesquisador pediu a italianos, residentes na Itália, que respondessem a pergunta, por escrito. As respostas estão dispostas no mapa abaixo. Para chegar ao mapa — resultado final do processo da análise dos dados — era preciso analisar as respostas obtidas através do procedimento de coleta.
Uma primeira observação foi a de que as respostas não contemplam todos os dialetos falados na Itália. Assim, por exemplo, não há amostra do correspondente griko para a sentença (Griko é um dialeto de origem grega falado no Salento e na Calábria). Ainda assim, ao lado da tradução para um italiano padrão (falado na região de Florença), e que corresponde a “si può fare”, há formas bastante diversas entre si, como “u putemu fari”, na Sicília, ou “se peu fa”, na Liguria ou, ainda “Xe poi far”, no Vêneto. Isto sem falar na sentença em alemão, “Wir schaffen das!”, no Trentino Alto-Adige.
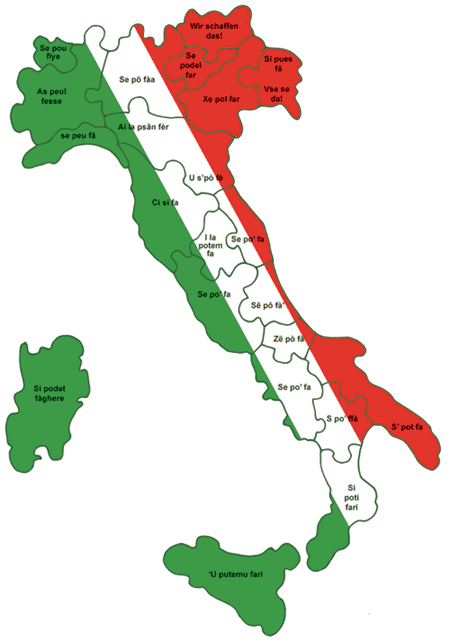
Mapa ilustrando “Yes, we can!” traduzido para diferentes dialetos italianos. Disponível em http://www.ilc.it/si-puo-fare.htm. (Acesso em 27/07/2020.)
O esquema requer que os dados sejam explicados, ou seja, que se construa um modelo para dar conta dos aspectos observados. Como, então, explicar a variação?
Há alguns elementos linguísticos e, outros, extralinguísticos que podem responder à questão e, consequentemente, compor um modelo explicativo: a variação causada por fatores linguísticos pode justificar a alternância “poi – po – peu”, por exemplo, ou “si – se – xe”.
Tal variação não é aleatória, mas resulta da semelhança articulatória entre os sons envolvidos. Fatos extralinguísticos, por sua vez, podem explicar a semelhança da produção registrada na Ligúria com o francês (já que essa região italiana faz fronteira com a França), ou o enunciado em alemão registrado em Trentito Alto-Adige, região de fronteira com Lichtenstein e Áustria.
Um modelamento dos dados, portanto, nos permite esperar flutuação nas formas em função da região geográfica em que são faladas e dos países com que fazem fronteira. O modelamento também nos permite esperar variabilidade entre vogais e consoantes, como já comentei. E é possível, ainda, cruzar a variabilidade entre vogais ou entre consoantes com cada região geográfica. Finalmente, a comunicação e a visualização do tratamento dos dados pode ser feita no formato que temos na imagem dos mapas acima.
Linguística e Computação: “(…) o diálogo entre essas áreas pode auxiliar linguistas a otimizar análise, documentação e armazenamento de dados, assim como pode auxiliar cientistas de computação a melhorarem o processamento e análise de dados de línguas naturais.“
Tarefas como a ilustrada no mapa são comumente desempenhadas por linguistas variacionistas. Eles documentam línguas, através da coleta de grandes conjuntos de dados; os conjuntos, por sua vez, são submetidos a análises e quantificados, por análise estatística, com a finalidade de testar hipóteses sobre a variação e sobre possíveis casos de mudanças linguísticas em curso. Esses casos são relacionados a fatores linguísticos e extralinguísticos que podem explicá-los. A relação entre essa perspectiva e a perspectiva de quem lida com ciência e banco de dados me parece nítida. Além disso, o diálogo entre essas áreas pode auxiliar linguistas a otimizar análise, documentação e armazenamento de dados, assim como pode auxiliar cientistas de computação a melhorarem o processamento e análise de dados de línguas naturais.
Uma interação mais próxima entre Computação e Linguística não me parece resumir-se às tarefas que mencionei anteriormente. Ao contrário, ela me parece ir além e levar à elaboração de ferramentas que utilizam línguas naturais para diferentes finalidades.
Essa via de mão dupla não é novidade para muitos e tem encontrado um terreno profícuo para seu desenvolvimento no processamento de linguagem natural, um universo não tão novo, mas altamente promissor.
Convergência entre Linguística e Computação:
modelos de análise e ferramentas tecnológicas
Se consideramos o desenvolvimento de ferramentas tecnológicas, fica evidente que a aproximação entre Computação e Linguística não é recente e se inicia, ainda na primeira metade do século XX, com o desenvolvimento de “máquinas falantes”, sistemas de tradução automática e sistemas simuladores de comunicação entre humano e máquina.
É preciso considerar que, naquele momento, tanto a tecnologia como os modelos de análise linguística disponíveis impunham limitações às ferramentas. Como resultado, sistemas de síntese produziam fala muito pouco parecida com a fala humana; a tradução automática fazia correspondência biunívoca entre as formas da língua de partida e da língua de chegada, e não conseguia dar conta de fatos como expressões idiomáticas; os primeiros chatbots, como o Eliza, simulavam diálogo com humanos através da combinação de padrões, que possibilitava ao sistema devolver perguntas a cada nova resposta do humano, mas as respostas tinham de se encaixar nos padrões que o sistema conhecia.
O desenvolvimento do Processamento de Linguagem Natural (PLN) possibilitou a melhoria dos sistemas de síntese de fala (caso do From Text to Speech), de tradução automática (caso do Google Translator) e dos chatbots (caso do Alexa ou o Siri), a tal ponto de se disseminarem e se popularizarem, sobretudo na última década. A sofisticação do PLN vai além, permitindo o tratamento de textos escritos, o que resulta na classificação de textos dos servidores de e-mail, em sistemas de conversão voice-to-text (como o Simon Says), em sistemas de buscas na internet.
Se, por um lado, essa sofisticação da área de PLN se vale do progresso da Linguística e da interação com ela, por outro oferece subsídios para que a Linguística elabore novas perspectivas para tratar a linguagem. Esse é o foco desta seção.
Antes de mais nada, é preciso notar que, se a perspectiva chomskyana trouxe maior poder explicativo para os modelos de análise linguística, as regras que geram estruturas de superfície a partir de uma estrutura profunda devem se aplicar a todos os dados de igual formato.
Embora isso formalmente seja possível, empiricamente nem sempre acontece. Assim, por exemplo, temos um fenômeno que nos faz pronunciar “pipino”, porque a vogal tônica influencia a pretônica, fazendo com que seja articulada com o mesmo grau (pequeno) de abertura de mandíbula. Por essa perspectiva, era de se esperar “pirigrino” para “perigrino”, mas essa forma nem sempre ocorre. Além disso, a regra não prevê “buneca”, porque a qualidade da vogal tônica, pela regra, não geraria uma vogal pretônica /u/. Então, os linguistas precisavam de modelos que oferecessem melhor tratamento de fenômenos como esse.
O PLN, segundo Eisenstein (2019), elabora um conjunto de métodos para “tornar a linguagem humana acessível aos computadores”. Ora, usar o tratamento que a Computação dá para a linguagem humana, sob a perspetiva de aprendizado de máquina, pode auxiliar os linguistas na busca por modelos mais poderosos.
A inferência bayesina, que avalia hipóteses formuladas a partir de um conjunto de dados e um modelo estatístico, e calcula valores para diferentes parâmetros desse modelo estatístico, permite que a Linguística considere variáveis como frequência de uso — não contemplada nos modelos de orientação chomskyana — e verifique padrões estruturais e funcionais de uma língua.
Para exemplificar como modelos bayesianos podem oferecer um tratamento adequado a fatos de línguas naturais, recorro à proposta de Pierrehumbert (no prelo). A autora — um dos principais expoentes da perspectiva da Linguística Probabilística — nota que é possível obter efeitos de probabilidade da ocorrência de um som, ou uma sequência deles, pela aplicação de modelos que estimam os padrões fonotáticos (sequências de sons permitidas numa língua), a partir de grandes conjuntos de dados da língua-alvo e levando em conta comportamentos linguísticos.
O exemplo oferecido por Pierrehumbert consiste na construção de um modelo probabilístico que estime o julgamento da aceitabilidade de sequências de sons em pseudopalavras, em função do tamanho da palavra. Pseudopalavras contêm sequências de sons permitidas numa língua, além de estruturas silábica e acentual possíveis nessa língua, mas não têm significado.
É preciso, então, propor um modelo probabilístico que verifique se certas sequências são consideradas possíveis numa língua, cruzando o comportamento linguístico com outra variável, o número de sílabas de uma palavra.
Para testar a acuidade do modelo probabilístico, Pierrehumbert recorre ao experimento de Frisch, Large, Pisoni (2000, apud Pierrehumbert, no prelo). Nesse experimento, em que falantes de inglês são solicitados a julgar a aceitabilidade de pseudopalavras, os autores verificam relação entre tamanho das pseudopalavras e frequência de ocorrência de estruturas silábicas, tal que o julgamento de aceitabilidade das pseudopalavras longas, contendo estruturas silábicas frequentes, equivale ao julgamento de aceitabilidade de pseudopalavras breves, contendo estruturas silábicas pouco frequentes.
Então, baseado no score fonotático mais simples e mais largamente utilizado na língua, o modelo proposto por Pierrehmbert assume que as palavras são geradas por um modelo bigrama, definido a partir de fonemas. Os scores são calculados pela multiplicação das probabilidades de transições, assumindo-se que cada transição é independente daquela que a precede e que o conjunto de probabilidade de dois eventos independentes é o produto das suas probabilidades individuais, obtido pela multiplicação das probabilidades de transições, conforme previsto pelo modelo de Markov. O julgamento de aceitabilidade do modelo probabilístico de Pierrehumbert chega aos resultados encontrados por Frisch, Large e Pisoni, o que leva a autora a afirmar que os resultados sugerem que probabilidades são cognitivamente relevantes para os humanos. Logo, um modelo de análise linguística deve levá-las em conta.
E tudo o mais…
Em seu manual sobre PLN, Eisenstein (2019) comenta que muitos dos problemas mais interessantes em PLN têm a linguagem como output. Nesse sentido, a geração de textos coloca novos desafios para a área. Para finalizar estas minhas considerações, vou focalizar a tarefa text-to-text, para ilustrar como a interação entre Computação e Linguística pode nos levar longe, seja do ponto de vista de técnicas computacionais, seja do ponto de vista do tratamento linguístico, quando se trata de automatizar processos relacionados à linguagem.
Ferramentas que fazem text-to-text obviamente têm a linguagem como entrada e saída e se prestam, por exemplo, à elaboração do resumo de um texto, ou a compilação de aspectos abordados em vários textos com o mesmo tema. Então, podemos pensar numa ferramenta que faça o resumo de um artigo científico sobre o COVID-19, ou numa ferramenta que tome vários textos sobre esse mesmo tema e compile discussões sobre a possível vulnerabilidade da mutação do vírus a uma vacina, reunindo pontos de vista convergentes e divergentes sobre o assunto.
Para isso, os textos de entrada necessitam de tratamento que permita ao sistema identificar por marcas linguísticas específicas da língua em que são escritos, elementos como os argumentos decorrentes dos resultados obtidos pelos estudos em que os textos se baseiam. Necessitam, igualmente, classificar os argumentos, a partir da verificação de convergência ou divergência entre eles, o que também requer tomar marcas linguísticas presentes nesses textos.
Recentemente, o MIT noticiou a criação de uma inteligência artificial que gera textos, no formato text-to-text. Altamente refinado, o sistema, denominado GPT-3, tem 175 bilhões de parâmetros, o que é fundamental para um bom modelo que lide com linguagem natural, como observa a notícia. Com esse valor de parâmetros para o aprendizado, o GPT-3 consegue ir muito além de gerar um resumo. Ele elabora textos de tipos diversos: desde um código de programação até um texto que reproduz o estilo de um escritor. Para essa última tarefa, basta que o usuário dê como entrada a sentença de um livro do escritor cujo estilo quer no texto a ser criado pelo GPT-3.
Isso representa um enorme avanço no processamento linguístico dos textos, já que o sistema precisa, no mínimo, distinguir entre tipos de textos – um código de programação, uma narrativa, um discurso político, por exemplo – e precisa “aprender” estilo, que é um aspecto sutil dos textos, porque carrega as marcas de autoria de quem escreve esses textos.
Se, por um lado, o GPT-3 tem a grande qualidade de gerar textos de modo altamente refinado, por outro lado ele pode ser perigoso, já que textos gerados por ele podem ser atribuídos – com as mais diferentes finalidades – a um autor humano que, efetivamente, não escreveu aquele texto. E será preciso, então, pensar numa maneira de identificar o autor do texto, distinguindo a inteligência artificial e o humano. Isto implica, claro, mais processamento de texto e a automatização de uma tarefa semelhante à que a Linguística forense realiza.
Como deve ficar claro, tudo o mais ainda está por ser feito, sobretudo quando se trata do português brasileiro. Sim, porque tarefas como a que eu descrevo nesta seção, assim como outras que envolvem o processamento de linguagem, são específicas de língua, ou seja, é preciso construir um gerador de textos para o PT-BR.
Tentar simplesmente usar um sistema de outra língua para lidar com o PT-BR não funciona, devido às diferenças estruturais, semânticas e pragmáticas entre as línguas naturais. E, nesse sentido, o diálogo entre Linguística e Computação, no Brasil, tem muito a avançar.
Referências
CHOMSKY, Noam. Syntactic Structures. London: Mouton, 1957.
COELHO, Izete Lehmhuhl; MONGUILHOTT, Isabel; MARTINS, Marco Antonio. Estudo diacrônico da inversão sujeito-verbo no português brasileiro: fenômenos correlacionados. In: RONCARATI, C.; ABRAÇADO, J. (orgs.). Português Brasileiro II- contato lingüístico, heterogeneidade e história. Niterói: EdUFF, 2008, p. 137-157.
EISENSTEIN, Jacob. Introduction to Natural Language Processing. Cambridge (MA): The MIT Press, 2019.
LEVELT, Willem. Speaking: from intention to articulation. Cambridge (MA): The MIT Press, 1989.
PIERREHUMBERT, Janet. 70+ years of Probabilistic Phonology. In: DRESHER, E.B.; van der HULST, H. (Eds.) Oxford Handbook on the History of Phonology. Oxford: Oxford University Press (no prelo).
SEDGEWICK, Robert; WAYNE, Kevin. Introduction to Programming in Java: An Interdisciplinary Approach. Pearson Education, 2017, 2nd. edition.
Sobre a Autora

Adelaide Hercília Pescatori Silva é Professora do Departamento de Literatura e Linguística da UFPR e do programa de pós-graduação em Letras na mesma Universidade. Bolsista PQ/CNPq. Pós-doutoranda do Programa de Pós-Graduação em Informática da UFPR, sob supervisão do prof. Dr. Fabiano Silva. Principais interesses: fonética acústica; fonologia de laboratório; processamento de linguagem natural. Editora da Gradus – Revista Brasileira de Fonologia de Laboratório. CV Lattes: http://lattes.cnpq.br/2441898800354402
Como citar este artigo:
SILVA, Adelaide Hercília Pescatori. 42 é a resposta. Qual é a pergunta sobre a relação entre Computação e Linguística e tudo o mais? SBC Horizontes, agosto 2020. ISSN: 2175-9235. Disponível em <http://horizontes.sbc.org.br/index.php/2020/08/42-e-a-resposta-qual-e-a-pergunta-sobre-a-relacao-entre-computacao-e-linguistica-e-tudo-o-mais/>. Acesso em: DD mês. AAAA.